从CPU的视角看函数调用
从CPU的视角看函数调用
函数调用这我熟啊——不就是将栈帧压入栈内吗
我还知道递归层次过多会导致StackOverflow呢,看吧举一反三多聪明!

那你知道最底层是如何实现函数调用的吗?整个函数调用的过程?

前言
如果想了解操作系统函数调用过程,我们从编程语言的角度上是很难看出什么端倪的,因为这一过程已经被封装地太死了
唯一的突破口既是汇编代码
接下来将使用一些调试工具对一段C语言函数调用对底层函数调用过程进行分析。
环境
WSL:
WSL 版本: 1.2.5.0
内核版本: 5.15.90.1
WSLg 版本: 1.0.51
MSRDC 版本: 1.2.3770
Direct3D 版本: 1.608.2-61064218
DXCore 版本: 10.0.25131.1002-220531-1700.rs-onecore-base2-hyp
Windows 版本: 10.0.22621.1702
OS Release
PRETTY_NAME=”Debian GNU/Linux 11 (bullseye)”
NAME=”Debian GNU/Linux”
VERSION_ID=”11”
VERSION=”11 (bullseye)”
VERSION_CODENAME=bullseye
ID=debian
HOME_URL=”https://www.debian.org/“
SUPPORT_URL=”https://www.debian.org/support“
BUG_REPORT_URL=”https://bugs.debian.org/“
调试工具
GNU gdb (Debian 10.1-1.7) 10.1.90.20210103-git
前期准备
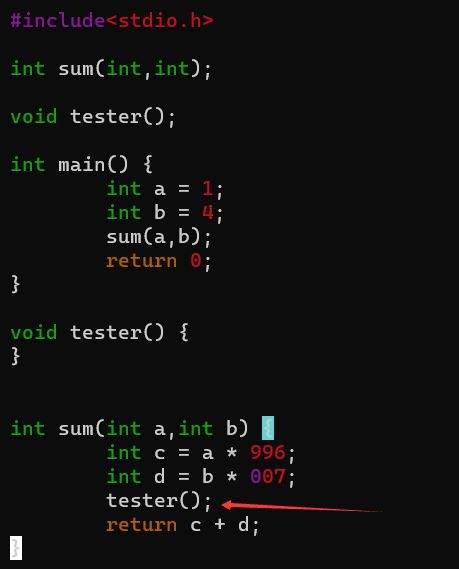
除上述实验环境外需要书写一份C语言函数调用源程序
1 |
|
执行指令编译源文件
➜ gcc -o function function.c
动态调试
main函数
对elf进行动态调试
➜ gdb function
在main函数处打断点
pwndbg> b main
Breakpoint 1 at 0x1129
执行程序
pwndbg> r
Starting program: /home/fool/c/function
Breakpoint 1, 0x0000555555555129 in main ()
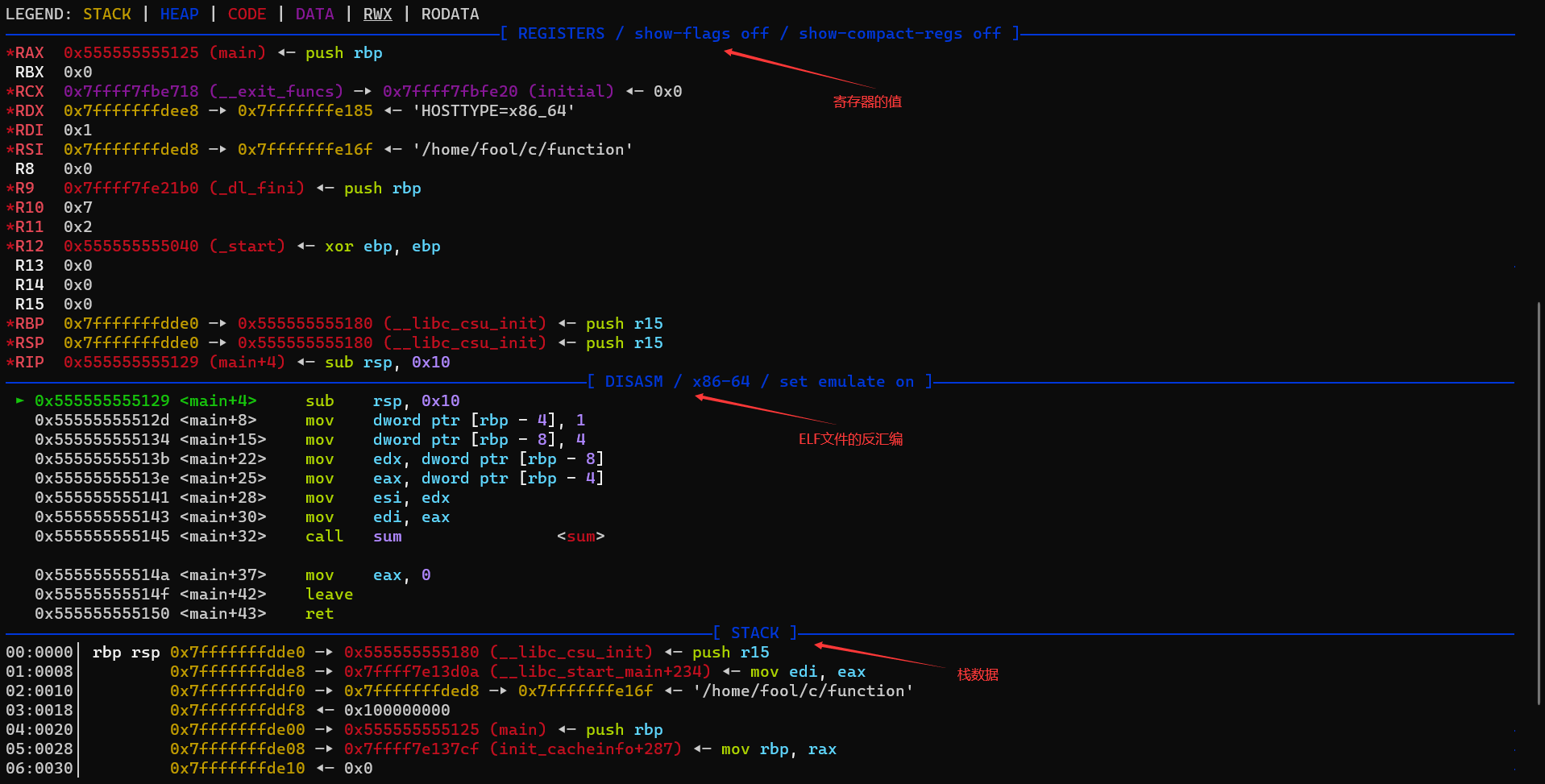
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
……
pwndbg的显示分为4个栏目
- 寄存器
- 汇编代码
- 栈内存
- 函数调用栈
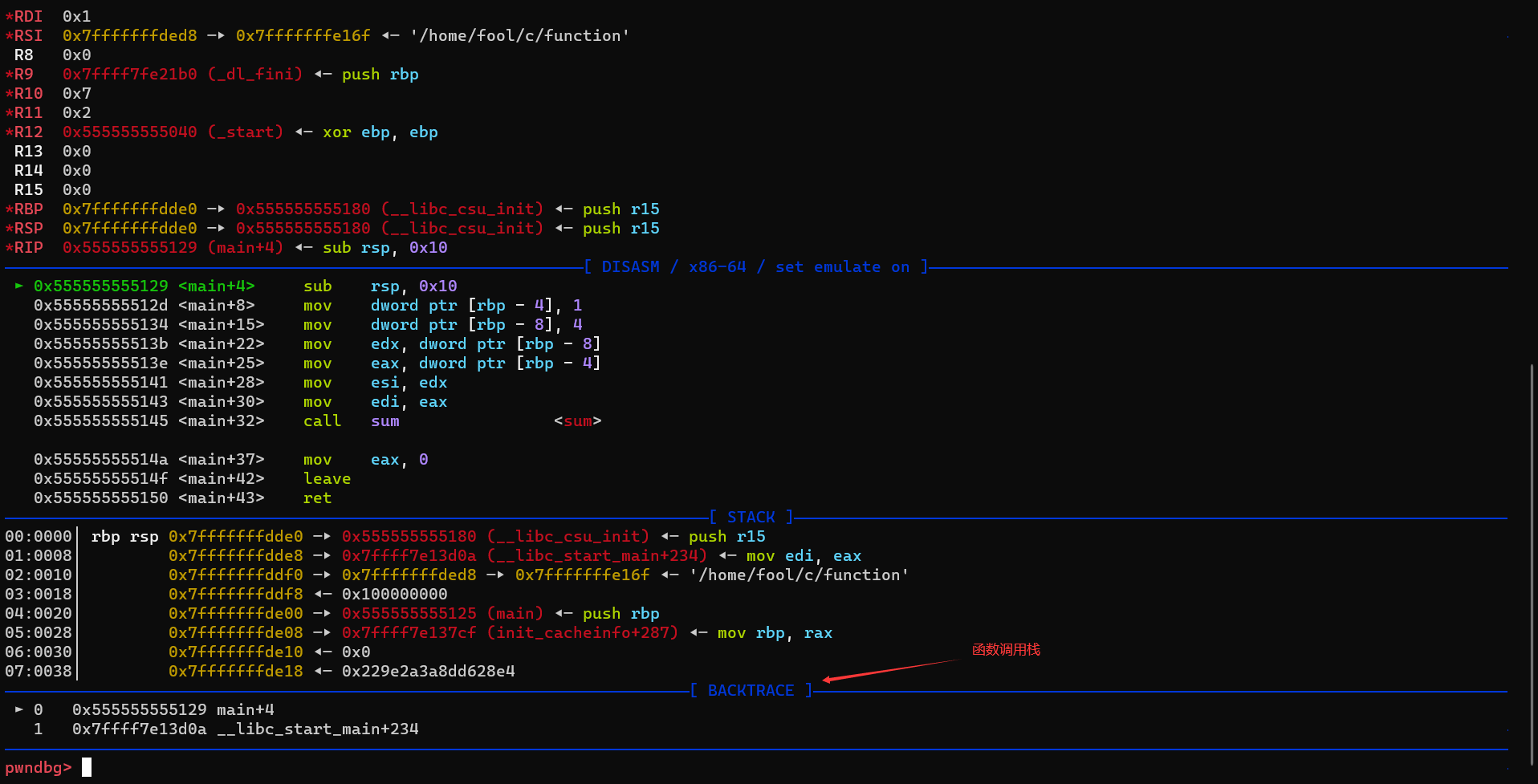
main函数调用流程

- 将rbp的值弹入栈内存
push rbp
因为当前的rbp是上一个调用方的栈基址
即__libc_start_main

- 为当前栈设置栈基地址
mov rbp,rsp
- 为当前栈帧分配空间
sub rsp,0x10
也就是说rbp和rsp中间的区域既是栈帧内存
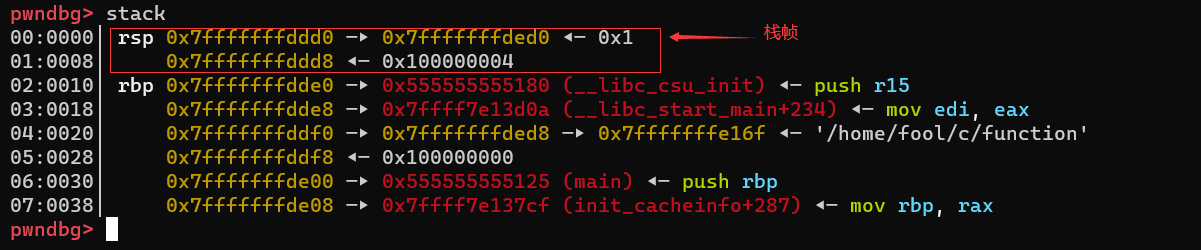
- 为栈局部变量赋值
即a,b成员变量
mov edx,DWORD PTR [rbp-0x8] ││ >0x55555555513e <main+25> mov eax,DWORD PTR [rbp-0x4]
查看栈空间

查看rbp(0x7fffffffdde0)上方8个字节空间的内存
小端序存储
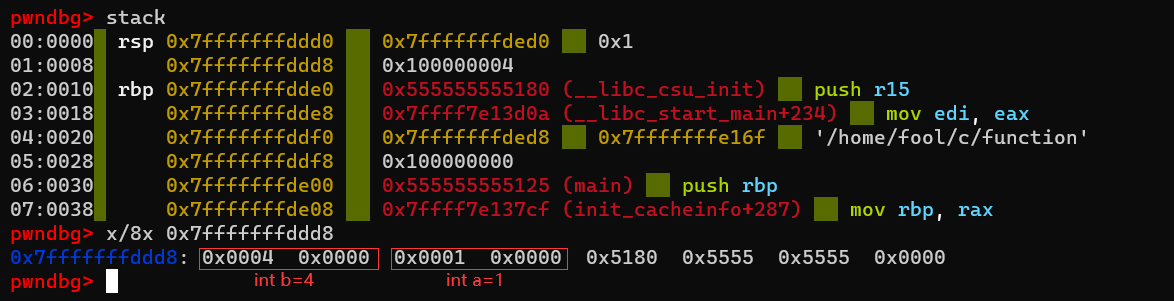
- 将a,b参数保存在寄存器中,以便后续函数调用传参
mov edx,DWORD PTR [rbp-0x8]
mov eax,DWORD PTR [rbp-0x4]
mov esi,edx
mov edi,eax
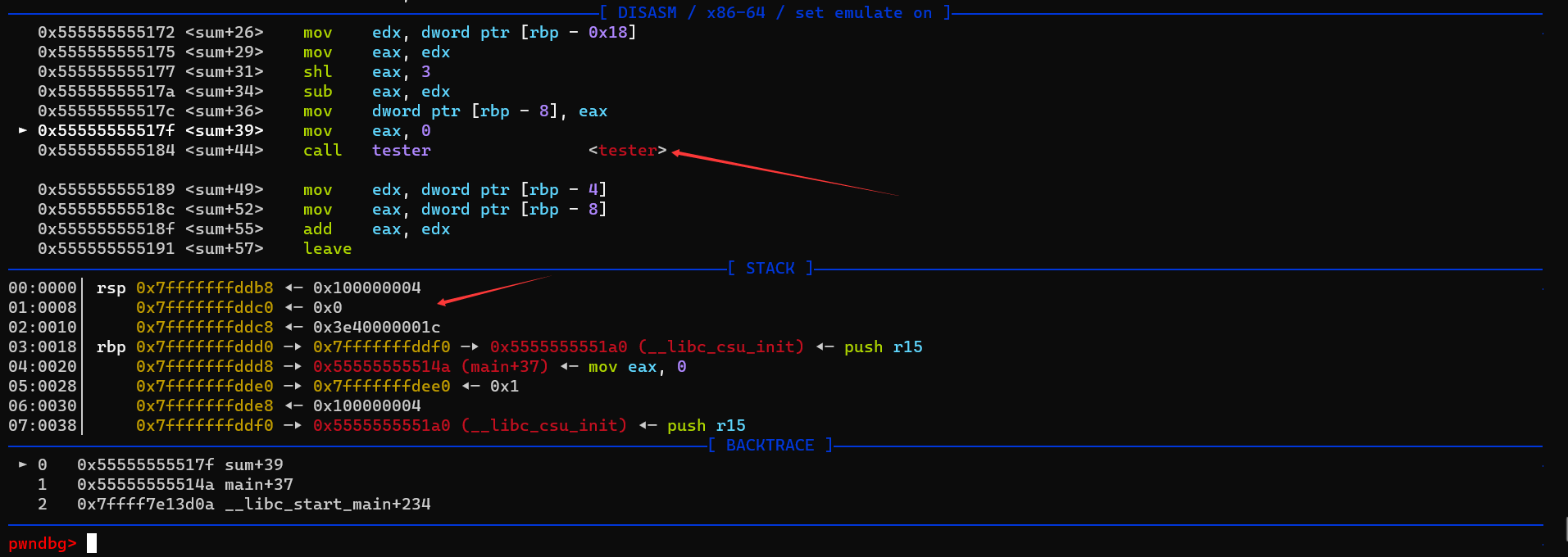
- 调用sum函数
call 0x555555555151
还会压入sum的eip
- 清空eax
mov eax,0x0
- 恢复ebp
leave
等价于
mov esp, ebp
pop ebp
- 恢复eip恢复调用方
ret (等效于pop eip)
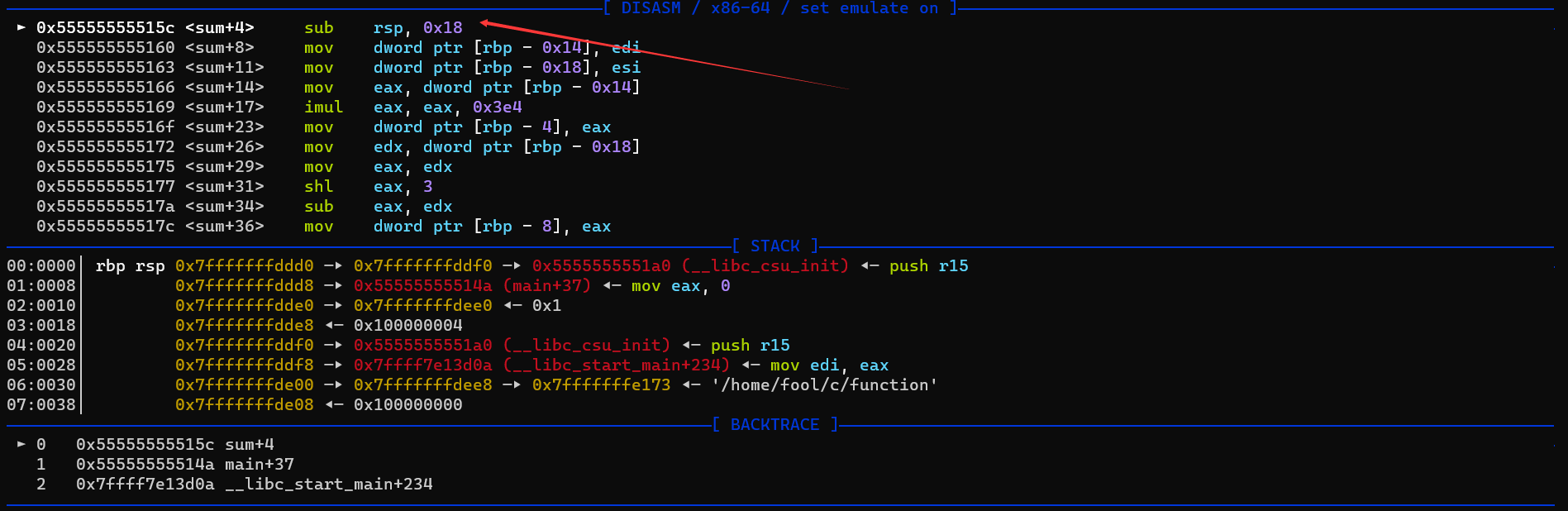
sum函数
- 保存栈帧
push rbp
- 传递函数参数
mov dword ptr [rbp - 0x14], edi
mov dword ptr [rbp - 0x18], esi
- 计算996 * a
mov eax, dword ptr [rbp - 0x14]
imul eax, eax, 0x3e4
mov dword ptr [rbp - 4], eax ; a变量地址
- 计算 007 * b
mov edx, dword ptr [rbp - 0x18]
mov eax, edx
shl eax, 3 ; 编译器优化 8 * b
sub eax, edx ; 8 * b - b 也就是7 * b
mov dword ptr [rbp - 8], eax ;变量b的地址
- 计算a + b
mov dword ptr [rbp - 8], eax
mov edx, dword ptr [rbp - 4]
mov eax, dword ptr [rbp - 8]
add eax, edx ; 返回值
- 恢复栈基地址
pop rbp
总结
函数调用过程
压入EIP指针
压入栈基址
开辟栈帧空间
局部变量/函数参数初始化,赋值
栈帧恢复
EIP指针恢复
栈帧本质
本质即RSP(栈顶)和RBP(栈顶)所指向构成的一段空间
栈帧结构

栈帧变动过程。
1.调用方会在栈中压入函数返回地址,以用于函数执行完成后返回。
2.被调方函数被执行后首先会备份一份调用方的基地址,最后开始开辟当前函数的栈帧。
3.栈帧的空间分配/移除本质只是ebp/esp的上/下移
4.函数执行完成后,后通过leave或者pop ebp移动ebp/esp
5.最后通过ret指令返回到调用方
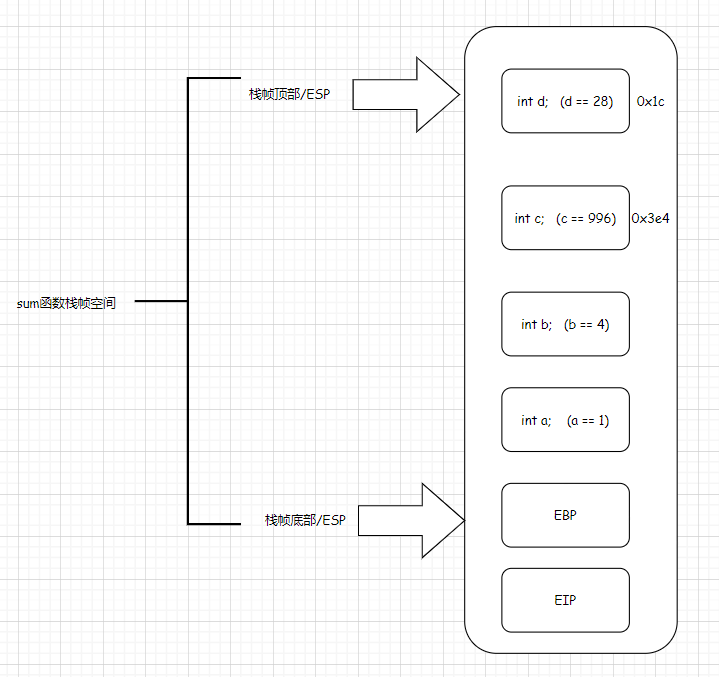
栈帧内存分配
1 | int sum(int a,int b) { |
question
但是实际调试的时候我们有发现一些问题?
Q1
在sum的汇编指令中我们没有看见rsp变动的部分
甚至当我们查看栈rbp,rsp的时候发现他们两个是重合的
这里我认为是编译器的一层优化,由于sum并没有调用其他的函数,所以没必要严格对栈顶进行更改
而且在寻址过程中主要用的也是rbp指针所以rsp是不是必要进行更改。

但是当我们在sum中调用了另外的函数的时候,这里就需要严格划分好栈帧的边界了
也就是说如果一个函数中没有调用其他函数,rsp指针是不需要进行移动的,因为移动会多消耗一条指令。
而栈内数据的定位是依靠的rbp,所以rsp就更没用了,编译器在编译的时候就会进行优化。
但是如果函数中调用了其他的函数,这里由于要区分不同的栈帧,rsp就必须得变换了。
Q2
内存分配的问题
1 | int sum(int a,int b) { |
根据我们之前的分析得到
2个函数参数+2个局部变量(2 * 4 + 2 * 4 = 16字节)
但是分配过程中却使用了0x18字节即24个字节。
这是为啥?

这边可能和编译器实现相关。
经过测试gnu的对于局部变量的内存分配满足如下规律
1.初始大小为8字节
2.当大小超过初始大小以后,每次扩容增加16字节。
(简答测试得到的结果,可能不准确,或许我们不必如此纠结,比较大小大一点不会造成太坏的影响)