常见的Unicode编码
基础概念
编码
编码是计算机最为常见的一部分,他所解决的是计算机”不认识”人所使用的自然语言的问题。
解决的思路也很简单,我们利用了计算机只认01 2进制的特点,既然计算机认识数字,那么我们就给所有的字符排一个号,类似于:
a : 97
A : 65
……
这样计算机就知道每个字符是什么了
Unicode编码
Unicode一般指统一码。 统一码(Unicode),也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
其实在Unicode之前经历过很多的编码,这里就默认大噶都有所了解啦~
ASCII、GB2312、BIG5、GBK
啥没听说?看看再来学呗~
Unicode是一种编码集,也就是前面所说的字符到数值的映射。
Map<Integer,Charactor>
Map<Charactor,Integer>
Unicode码点
即Unicode编码所对应的数值
目前Unicode最大的码点为0x10FFFF
编码实现
Unicode只是一套规范,这套规范里面给出了,具体每个字符到一个整数值的映射关系。
而且这个套编码规范的表还在不断地收入一些奇奇怪怪用不到地字符,如何有效地对这些奇怪地字符进行编码就成了一个问题。
而而且还要考虑到要用到计算机实际的操作过程中,内存占用肯定是不能忽略的方式。所以就衍生出了一些所谓的Unicode的编码实现。
即定长编码:
如UTF-32(每个UTF-32单元都是32位,由于UTF-32每个单元都是32位所以是可以完全容纳所有Unicode字符的)
变长编码:
如UTF-16(每个UTF-16单元都是16位的,由于Unicode至少需要24位所以,UTF-16会对部分Unicode码点进行切分,然后使用两个单元表示这段区间的码点,从而实现用16位变长的编码表示)
如UTF-8(每个UFT-8单元都是8位,但是由于要映射到24位,所以UTF-8对于一个Unicode的码点可能是1个UTF-8单元,可能是2个,也可能是3个)
UTF-32
最简单的一种编码,将Unicode码点直接对应。
比如
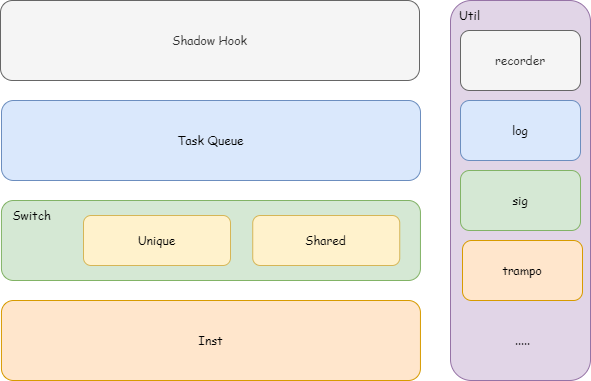
“你好世界😄”
编码到最后也就是
如果去查看unicode码表你会发现他们呢是一一对应的关系
0x00004F60 (你)
0x0000597D (好)
0x00004E16 (世)
0x0000754C (界)
0x0001F604 (😄)
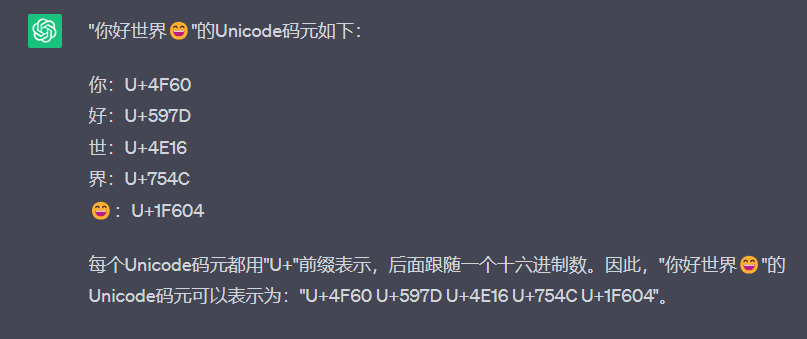
(如果看到这的同学有尝试过使用线上的一些解码工具进行解码的,奉劝一句别用了)

不知道是我运气不好还是啥的,这些网站解出来的Unicode码元都是错的,他们接出来的都是UTF-16编码的码元,而不是Unicode码元
UTF-16
UTF-16是非定长编码,但一个UTF-16码元是16位即2字节
所谓的非定长指的是一个Unicode码元与UTF-16码元不是一对一的。(很好理解啊,Unicode码元最大位0x10FFFF,而UTF-16只有16位肯定没办法一一对应)
那如何进行编码?
即
Unicode
0x000000 ~ 0x00FFFF直接对应UTF-16码元
0x010000 ~ 0x10FFFF则需要对应两个UTF-16码元
单个码元是直接对应
两个码元如何对应?
比如 😄(unicode:0x01F604)
1.将unicode减去0x010000 (0x01F604 - 0x010000 = 0x00F604)(这样范围缩小到0x00000,0xFFFFF,一共20位)
2.将20位unicode分两半,前10位和10位(0x3D,0x204)
3.前10位加上0xD800(0xD800 + 0x3D = 0xD83D )(范围锁定在0xD800~0xDBFF)
4.后10位加上0xDC00(0xDC00 + 0x204 = 0xDE04)(范围锁定在0xDC00~0xDFFF)
5.拼接两位数字得到编码(0xD83D 0xDE04)
注意:
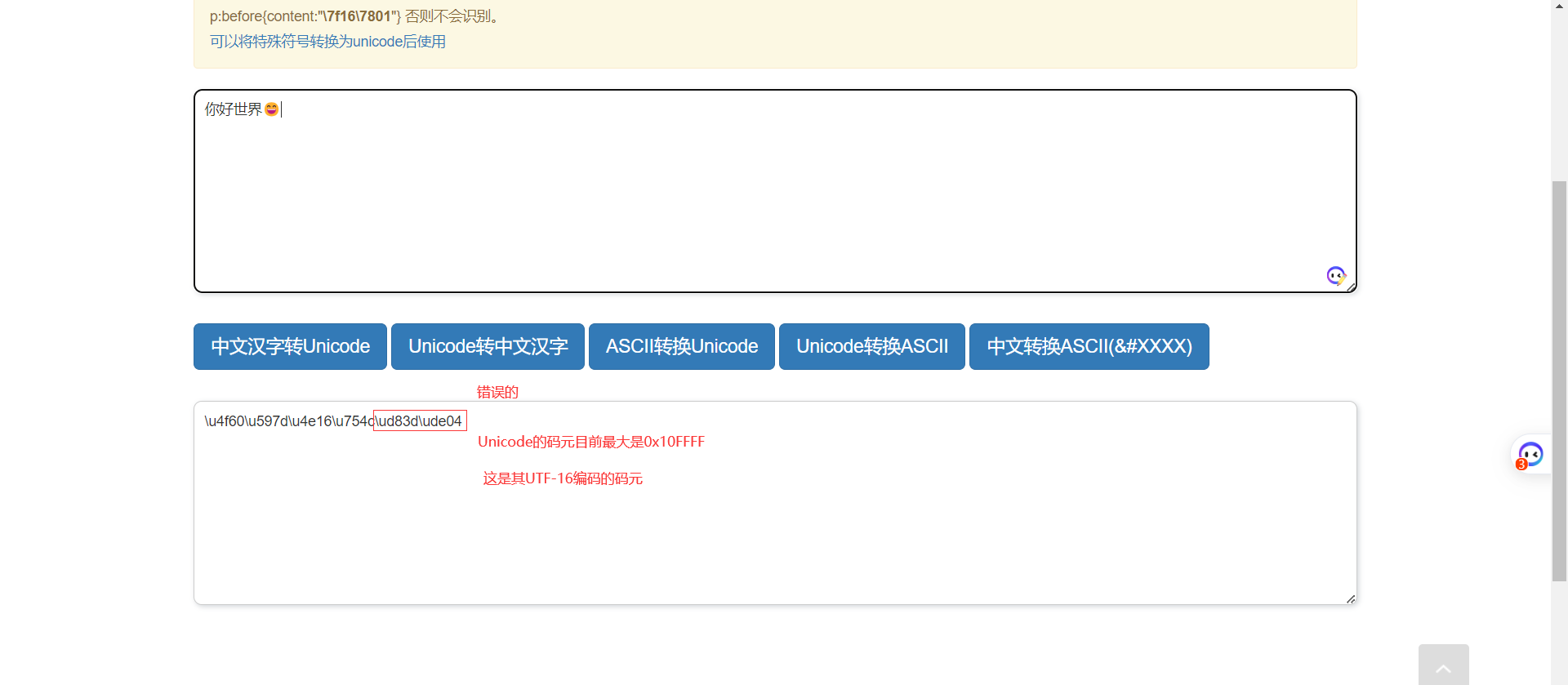
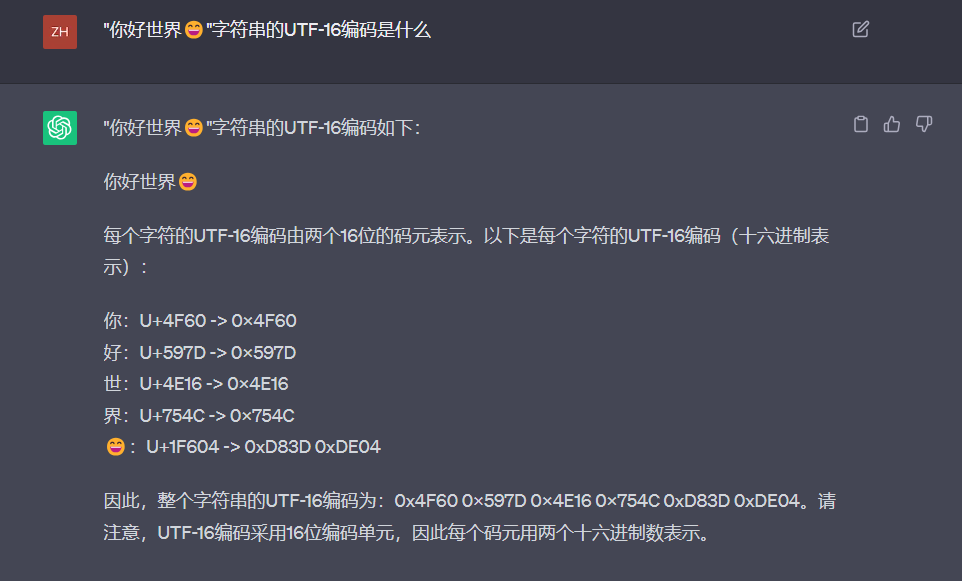
“你好世界😄”的UTF-16编码
0x4F60 (你)
0x597D (好)
0x4E16 (世)
0x754C (界)
0xD83D 0xDE04 (😄)
UTF-8
UTF-8的一个码元是8位即字节
一个Unicode的码点可能对应1,2,3,4个UTF-8码元对应如下
0x00-0x7F 0XXXXXXX (1个个UTF-8码元)
0x80-0x7FF 110XXXXX 10XXXXXX (2个UTF-8码元)
0x800-0xFFFF 1110XXXX 10XXXXXX 10XXXXXX(3个UTF-8码元)
0x10000-0x10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX (4个UTF-8码元)
其中X表示实际的Unicode值,
- 比如’a’
unicode为0x0061,属于第一梯度编码后结果为
0x61
- 比如®
unicode为0x00AE,属于第二梯度编码后结果为
0xC2 0xAE
- 比如ࠀ
unicode为0x0800,属于第三梯度编码后结果为
0xE0 0xA0 0x80
- 比如😄
unicode为0x1F604 ,属于第四梯度编码结果为
0xF0 0x9F 0x98 0x84
小结
UTF-32/UTF-16/UTF-8编码都有一定的特色。
其中UTF-32由于编码长度较大。导致存储上内存占用比较多,所以一般很少采用。
然后UTF-16和UTF-32对于不同场景下会有不同的用途
- UTF-16由于码元为16位,而且针对于中文字符编码友好(比起UTF-8 3字节)所以纯中文的情况下可以优先考虑使用UTF-16,更节省空间
- UTF-8比较适用于通用场景,比如中文英文,Emoji标签各类字符都有的情况,或者英文字符多的情况使用能节省一定的空间
其他编码
ASCII
- 这个都懂吧
GBK
汉字内码扩展规范,简称GBK,全名为《汉字内码扩展规范(GBK)》1.0版,由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司和电子工业部科技与质量监督司1995年12月15日联合以《技术标函[1995]229号》文件的形式公布。 GBK共收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。
注:
编码方式
字符采用类似于UTF-16的编码
GBK的编码分为两种一种是单字节编码,一种是双字节编码
- 单字节编码
所处范围为00~7F(正好是ASCII嘛的范围)
- 双字节编码
第一个字节所处范围为81–FE
第二个字节所处范围为一部分在40–7E,其他领域在80–FE。
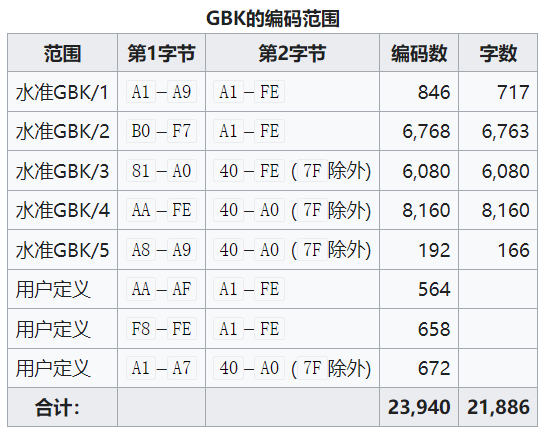
如果使用空间进行展示
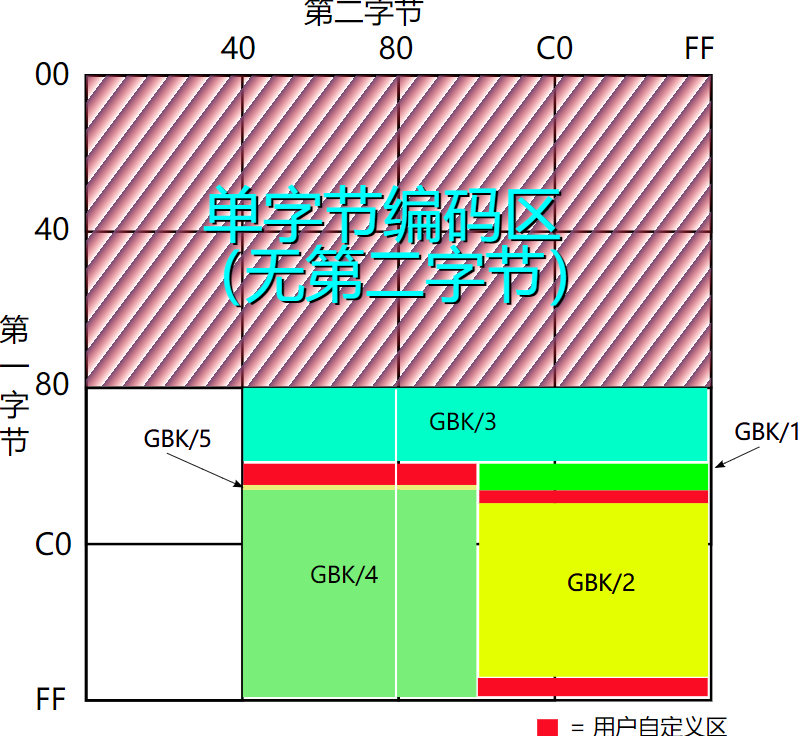
具体怎么编码的就没必要了解了相当于就是查一张BIG表单
番外
乱码神兽“锟斤拷”
大致描述一些复现过程
1.假如你有一个GBK编码的文本文件
2.你现在通过UTF-8编码打开它,你现在并不知道他的编码是什么所以打开过程肯定会出现乱码
3.然后使用UTF-8编码对文件进行了修改,一些大聪明编辑器会对文件无法显示的内容做替换
4.然后你现在又把编码改回了GBK,然后你就抓到了乱码神兽锟斤拷。
所以这样的乱码出现的原因就是:
你用错误的编码对文件进行了修改,导致编辑器对全局不可见字符进行了替换导致编码切换回来的时候出现的异常。
接着我们使用
大聪明VScode编辑器尝试一下
1.创建GBK文件
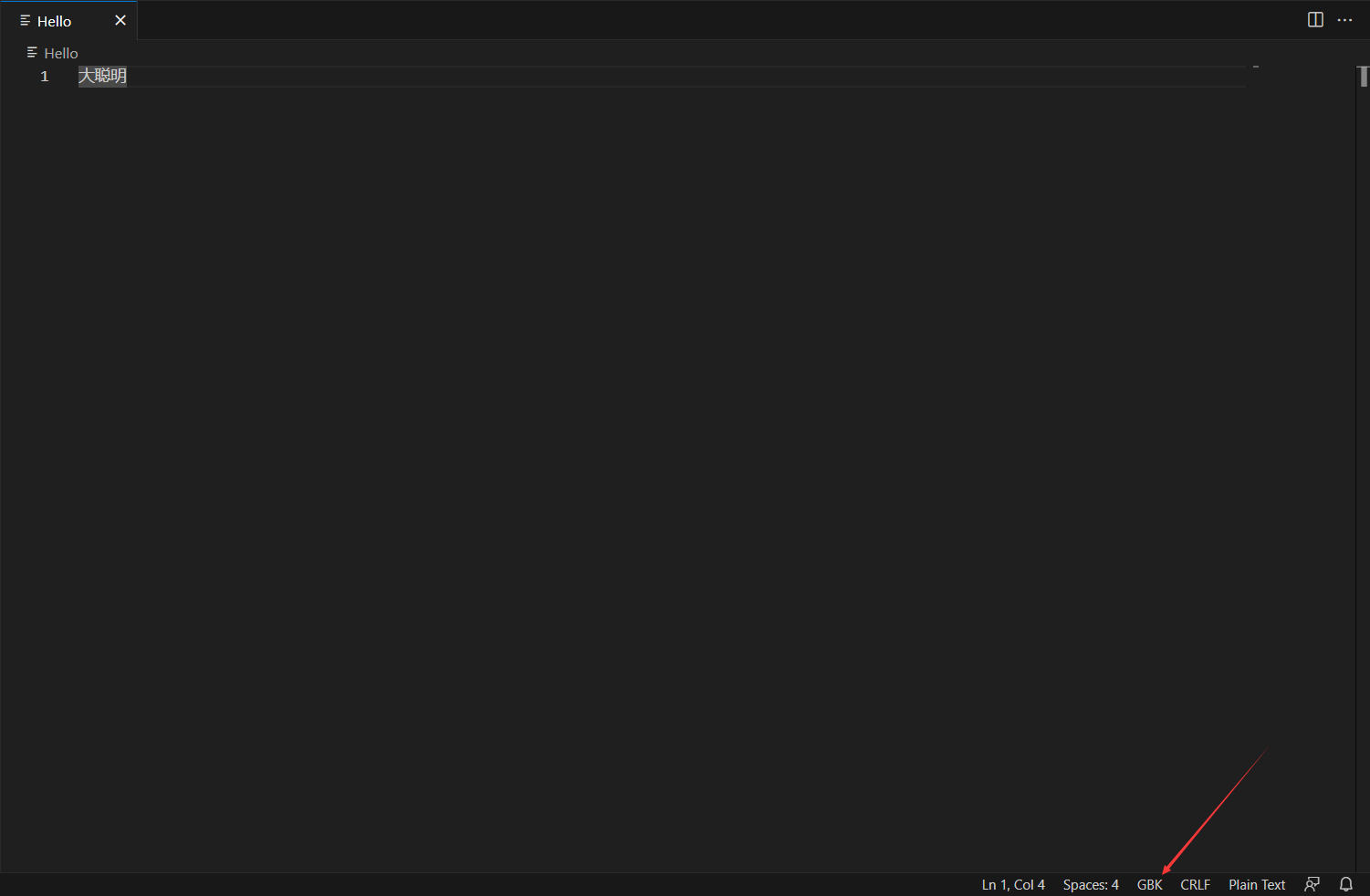
2.修改编码并进行修改

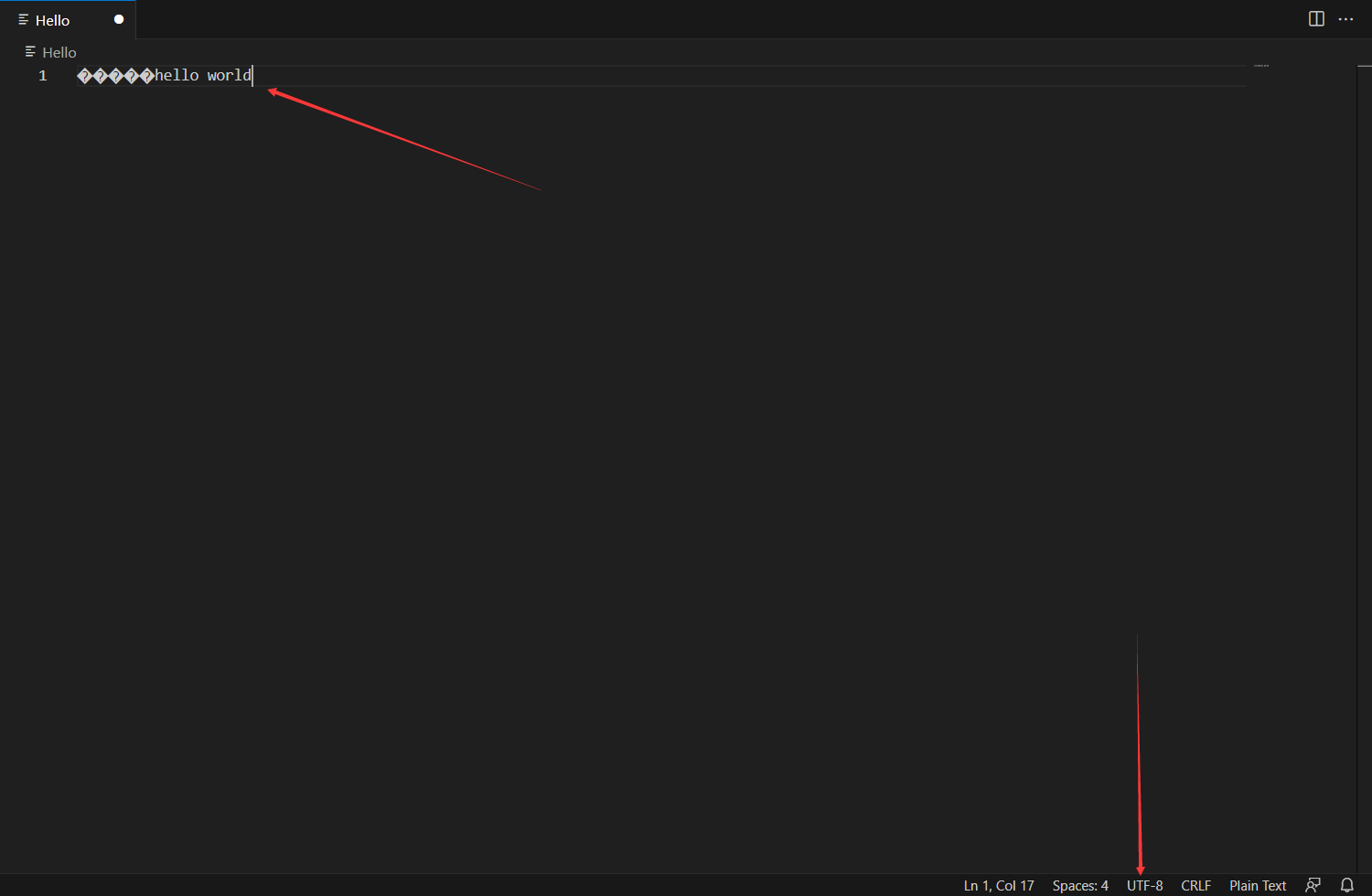
3.切换回来,成功活捉锟斤拷
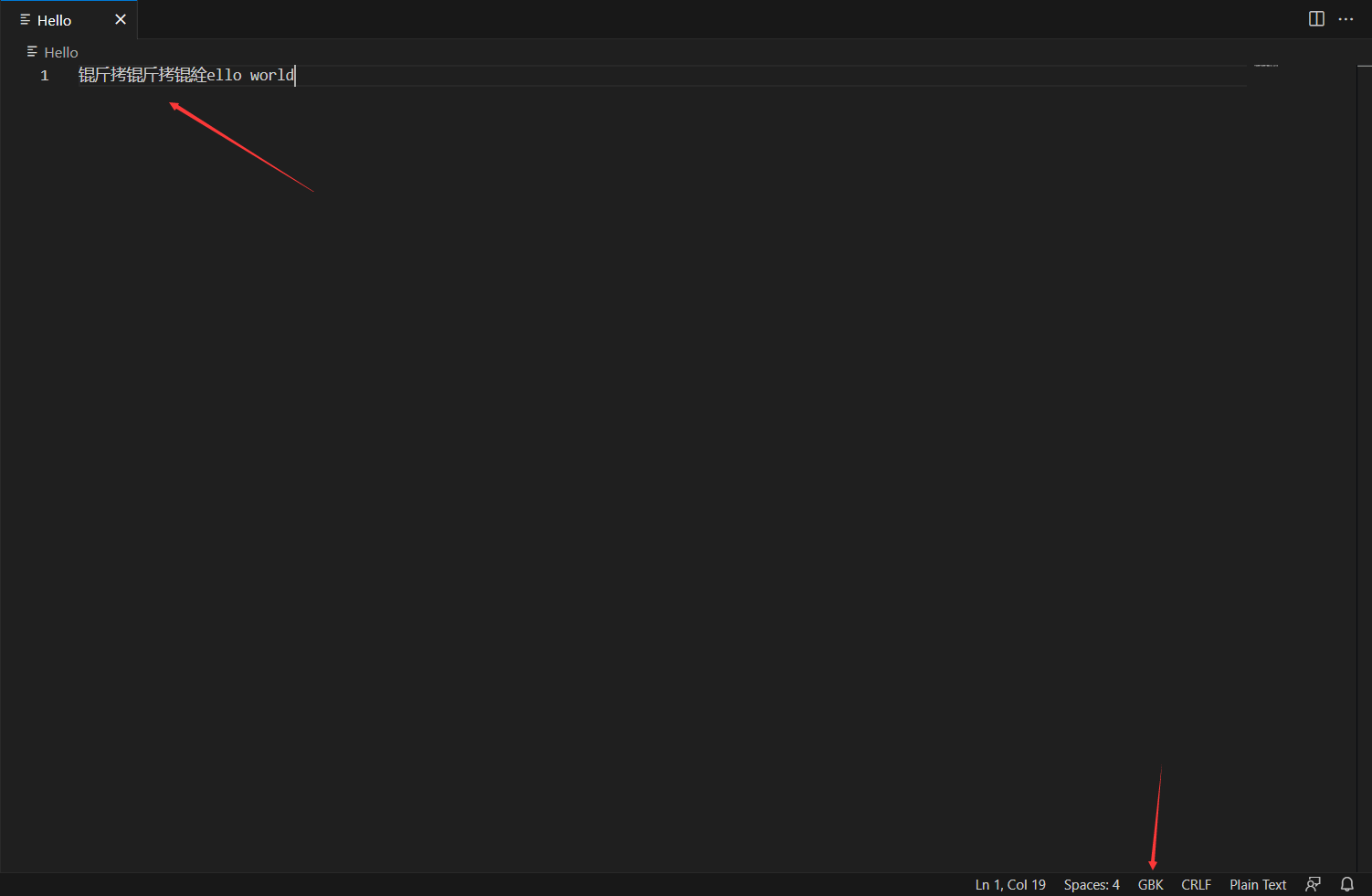
所以这说明了什么道理?
遇见不知道是啥编码的文件,别手贱乱修改!!