C语言内联汇编
ASM
此处的ASM指的是C语言中的asm关键字
asm关键字可以用于内联汇编代码,即在C文件中声明一部分汇编代码,最后在编译器的作用下,实现一部分C语言无法实现的功能。
概念
C语言的编译过程
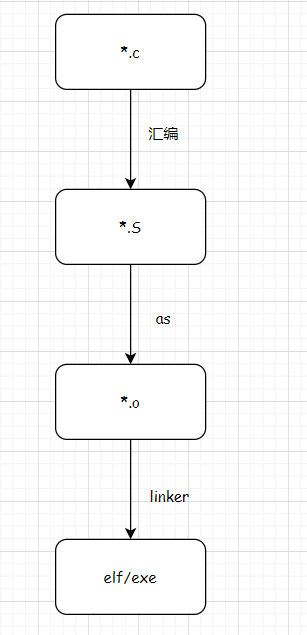
我们知道C语言
1.会汇编为assembly(汇编语言)
2.汇编语言会在汇编器(as)的作用下变为object文件。
3.最后通过会linker链接为elf/exe文件。
为什么需要asm
前面其实有说过asm是C语言中的一个关键字
这个关键字的功能就是使用assembly去实现一部分功能。
这里有一个问题☝️
C语言会有无法实现的功能需要assembly去实现?
有吗?没有吗?
肯定是有的
其实有很多。
我们C语言所有的能力都是基于汇编的。
如果没有汇编,那么就C语言什么都做不了。
所有的C语言特性都是基于assembly去实现的。
那么问题来了?C语言的语言特性能完成所有事情吗?
并不能,不然系统调用,系统注册,操控寄存器,控制屏幕。
这部分内容assembly能实现吗?
太能了,assembly虽然怪难写的,但是人家是正经的,所有的功能都能实现。
所以就很明确了,C语言所有不能实现的能力都需要借助内联汇编去实现
现代编程语言架构
从上面推断,我们可以得知,如下的依赖层级关系图。(仅个人思考)
Java、Python、Javascript这些典型的高级语言
运行环境依赖C/C++去实现。
C/C++运行过程中部分无法实现的能力借助汇编去实现。
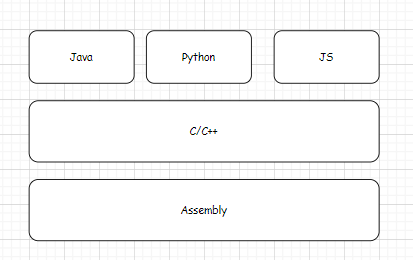
其实从这里我们可以知道一个事情。
“C/C++不是万能的,汇编才是”
(如果不把asm内联引入的代码纳入C/C++的范畴的话)
C语言如何内联汇编
大多是的编译器的内联方式都是通过一个关键字实现。
通过向关键字内传入一些汇编代码 & 固定的语法格式。
指定的编译器读取内容以后进行解析,最后对内联的汇编代码处理。
本文主要是对GNU GCC内联汇编进行介绍。
在GNU GCC中有两张方式可以内联汇编
- Base Asm
- Extended Asm
Basic Asm
基础版,特点就是简单,缺点就是不能有任何的“操作数“
简单来说就是单方面调用assembly,不能传入C变量。
语法格式如下
1 | asm asm-qualifiers ( AssemblerInstructions ) |
asm
关键字(告诉编译器,后面开始编写内联代码了)
asm-qualifiers
限定词,可以理解为,对内联的模式进行选择。
volatile
默认选项,编译器不会对内联的汇编指令进行优化。原原本本输出
(因为现代的编译器通常会对代码进行优化,优化过程会怎么改代码就不得而知了)
inline
与volatile相反,会开启优化,会对部分的代码进行优化
下面会对通过asm关键字内联一个hello world
首先我们先查询一下write的系统系统调用表

1 |
|
输出结果

Extended Asm
上面的示例其实我们可以发现。
内联asm如果不能调用C语言的一些语言特性。
其实还不如直接写asm代码好用。
所以就有了Extended Asm的出现。
Extended Asm在之前Basic Asm的基础上进行了扩展。
这个扩展就是——内联的汇编代码,可以读取、写入C语言的变量,并且可以跳转到C语言的Label标记
With extended
asmyou can read and write C variables from assembler and perform jumps from assembler code to C labels. Extendedasmsyntax uses colons (‘:’) to delimit the operand parameters after the assembler template:
这个就是Extended Asm的语法结构
1 | asm asm-qualifiers ( AssemblerTemplate |
asm-qualifiers
在原来volatile和inline的基础上多了一个goto
goto
This qualifier informs the compiler that the asm statement may perform a jump to one of the labels listed in the GotoLabels. See GotoLabels.
暗示编译器,内联的代码中可能会有jump到c语言label的行为
AssemblerTemplate
同Basic Asm是一个Asm的模板,不一样的是,多了几个占位符。
‘%%’
等同于%,这里起的是转义的意味。
因为有%0 %1(input,output的占位符,可能是memory可能是寄存器)的存在。
为了区分%和%n就有了这么一层转义
‘%=’
Outputs a number that is unique to each instance of the
asmstatement in the entire compilation. This option is useful when creating local labels and referring to them multiple times in a single template that generates multiple assembler instructions.生成一个asm代码块内唯一的数字(怎么生成的我也不知道。)
‘%{’,‘%|’,‘%}’
转义.因为{|}在template中其他含义
%n
即%1 %2 %3,代指input or output的占位。
OutputOperands
1
[ [asmSymbolicName] ] constraint (cvariablename)
asmSymbolicName
占位符名称 %[Value]
(类似于我们在高级编程语言的字符串占位符,template里面写一个占位,然后在output里面写一个占位。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main() {
int input_value = 42;
int output_value;
// 在内联汇编中使用 %[input] 和 %[output] 来指代输入和输出操作数
asm(
"movl %[input], %[output]"
: [output] "=r" (output_value) // %[output] 表示输出操作数
: [input] "r" (input_value) // %[input] 表示输入操作数
);
printf("Input: %d, Output: %d\n", input_value, output_value);
return 0;
}如果不使用asmSymbolicName:
默认的读取顺序就是这样
——output->input分别是%0,%1,%2,……,%n
%n (eg: %0,%1,%2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int main()
{
int input_value = 42;
int output_value;
// 使用 %= 生成唯一标识符并在内联汇编中使用
asm(
"movl %1,%0;"
: "=r"(output_value)
: "r"(input_value)
);
printf("Input: %d, Output: %d\n", input_value, output_value);
return 0;
}constraint
A string constant specifying constraints on the placement of the operand
相当于是给output设置参数配置
参数异常的多,具体可见官方文档
“m”
表明限定的值(输入or输出)可以是内存
“o”
允许一个内存操作数,但寻址方式是可偏移的。即,该地址加上一个小的偏移量可以得到一个有效的地址。
“v”
内存操作,但是满足m限制,但不满足o限制的条件
“<”
内存操作自动减操作
“>”
内存操作符自动加操作。
“r”
表明限定的值,使用寄存器进行传递。
“i”
表明输入的值,可以是一个立即数
“n”
同i,许多系统不能支持小于一个字的操作数的汇编时常量。对于这些操作数,约束应该使用’n’而不是’i’。
“g”
‘I’, ‘J’, ‘K’, … ‘P’ / ‘E’ / ‘F’ / ‘G’, ‘H’ / ‘s’
立即数。
‘g’
允许使用所有通用寄存器,内存,立即数
‘X’
允许所有的操作符
‘0’, ‘1’, ‘2’, … ‘9’
允许使用与指定操作数编号相匹配的操作数。
‘p’
允许使用有效的内存地址作为操作数
cvariablename
C语言变量名称
InputOperands
1
[ [asmSymbolicName] ] constraint (cexpression)
asmSymbolicName
同OutputOperands中的asmSymbolicName
constraint
input 不能以‘=’ or ‘+’作为constraint开头。
cexpression
C关键字 & C表达式
Clobbers
告知编译器,我们做了设置/改动,以便后面编译器接手。
- “cc”
告知编译器修改了flag寄存器
- memory
告知我们进行了内存的读取
了解了Extended Asm的妙处以后,我们试着来使用一下打印Hello World!
代码少了,逻辑也更清晰了
1 |
|
最后一个灵魂问题。
学了这个以后有什么用?
其实没什么用,日常中应该很少会用到。
但是,这对我们去阅读一些底层的代码有好处。
比如内核,glibc等源代码。
我们至少勉强能看懂一点人家是在干嘛,通过查阅检索等方式能迅速理解。
参考
GNU GCC官方文档