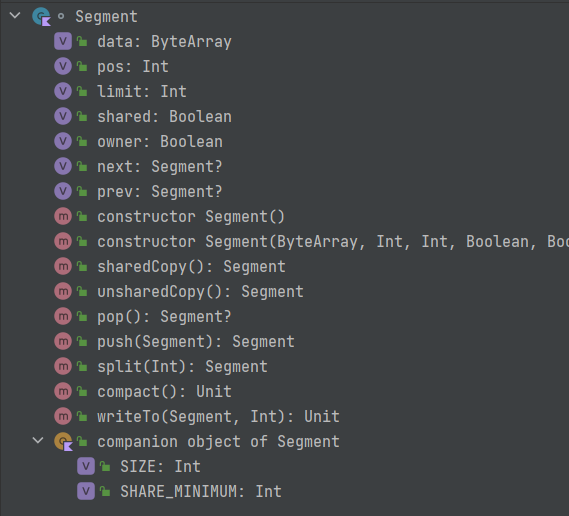
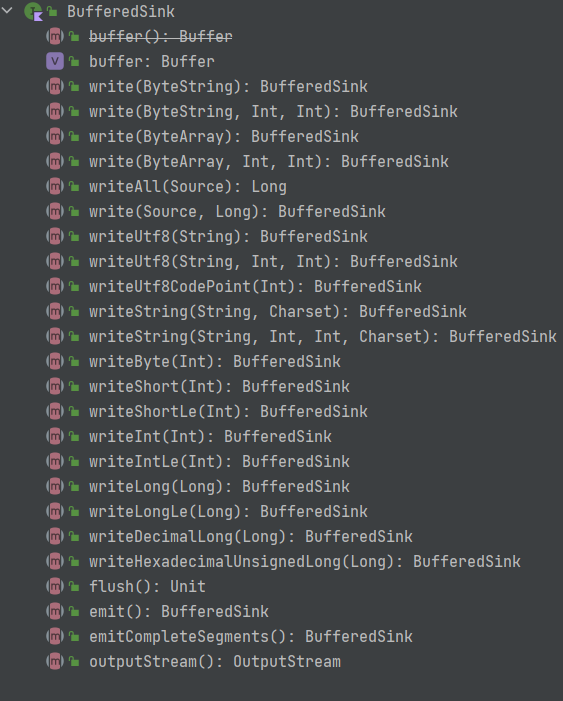
// 将当前节点弹出 funpop(): Segment? { val result = if (next !== this) next elsenull prev!!.next = next next!!.prev = prev next = null prev = null return result }
// 在循环队列的指定位置加入一个元素 funpush(segment: Segment): Segment { segment.prev = this segment.next = next next!!.prev = segment next = segment return segment }
/** A sentinel segment to indicate that the linked list is currently being modified. */ privateval LOCK = Segment(ByteArray(0), pos = 0, limit = 0, shared = false, owner = false)
// hash桶,也是缓存的segment的地方 privateval hashBuckets: Array<AtomicReference<Segment?>> = Array(HASH_BUCKET_COUNT) { AtomicReference<Segment?>() // null value implies an empty bucket }
actualval byteCount: Int get() { val first = firstRef().get() ?: return0 return first.limit }
@JvmStatic actualfuntake(): Segment { // 获取hash桶中的句柄 val firstRef = firstRef() // 加锁 val first = firstRef.getAndSet(LOCK) when { // 已经锁定 first === LOCK -> { // 防止等待,直接new返回 return Segment() } first == null -> { // 获取锁但是为缓存 firstRef.set(null) return Segment() } else -> { //获取锁并且有缓存,使用缓存 firstRef.set(first.next) first.next = null first.limit = 0 return first } } }
@JvmStatic actualfunrecycle(segment: Segment) { require(segment.next == null && segment.prev == null) // 如果当前segment被共享,无法回收 if (segment.shared) return// This segment cannot be recycled. // 获取句柄 val firstRef = firstRef() // 加锁 val first = firstRef.getAndSet(LOCK) // 没有获取锁 if (first === LOCK) return // 获取到当前线程池的缓存量(limit在被回收以后被赋予了新的意义) val firstLimit = first?.limit ?: 0 // actual val MAX_SIZE = 64 * 1024 (64kb) if (firstLimit >= MAX_SIZE) { firstRef.set(first) // Pool is full. return }
segment.next = first segment.pos = 0 // 累加Segment Data Size segment.limit = firstLimit + Segment.SIZE // 头插法设置进入hash桶 firstRef.set(segment) }
privatefunfirstRef(): AtomicReference<Segment?> { // Get a value in [0..HASH_BUCKET_COUNT) based on the current thread. val hashBucket = (Thread.currentThread().id and (HASH_BUCKET_COUNT - 1L)).toInt() return hashBuckets[hashBucket] } }
internalinlinefun Buffer.commonWriteLong(v: Long): Buffer { val tail = writableSegment(8) valdata = tail.data var limit = tail.limit data[limit++] = (v ushr 56 and 0xffL).toByte() data[limit++] = (v ushr 48 and 0xffL).toByte() data[limit++] = (v ushr 40 and 0xffL).toByte() data[limit++] = (v ushr 32 and 0xffL).toByte() data[limit++] = (v ushr 24 and 0xffL).toByte() data[limit++] = (v ushr 16 and 0xffL).toByte() data[limit++] = (v ushr 8 and 0xffL).toByte() // ktlint-disable no-multi-spaces data[limit++] = (v and 0xffL).toByte() // ktlint-disable no-multi-spaces tail.limit = limit size += 8L returnthis }
类似的writeXXX都是会先调用writableSegment接着修改data。
其中writableSegment是用于准备足够的空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
internalinlinefun Buffer.commonWritableSegment(minimumCapacity: Int): Segment { require(minimumCapacity >= 1 && minimumCapacity <= Segment.SIZE) { "unexpected capacity" } // 如果head为null初始化 if (head == null) { val result = SegmentPool.take() // Acquire a first segment. head = result result.prev = result result.next = result return result }
var tail = head!!.prev // 如果内存容量不足minimumCapacity开辟新的空间 if (tail!!.limit + minimumCapacity > Segment.SIZE || !tail.owner) { tail = tail.push(SegmentPool.take()) // Append a new empty segment to fill up. } return tail }
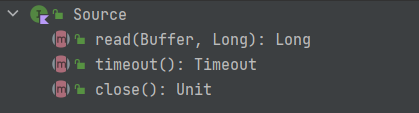
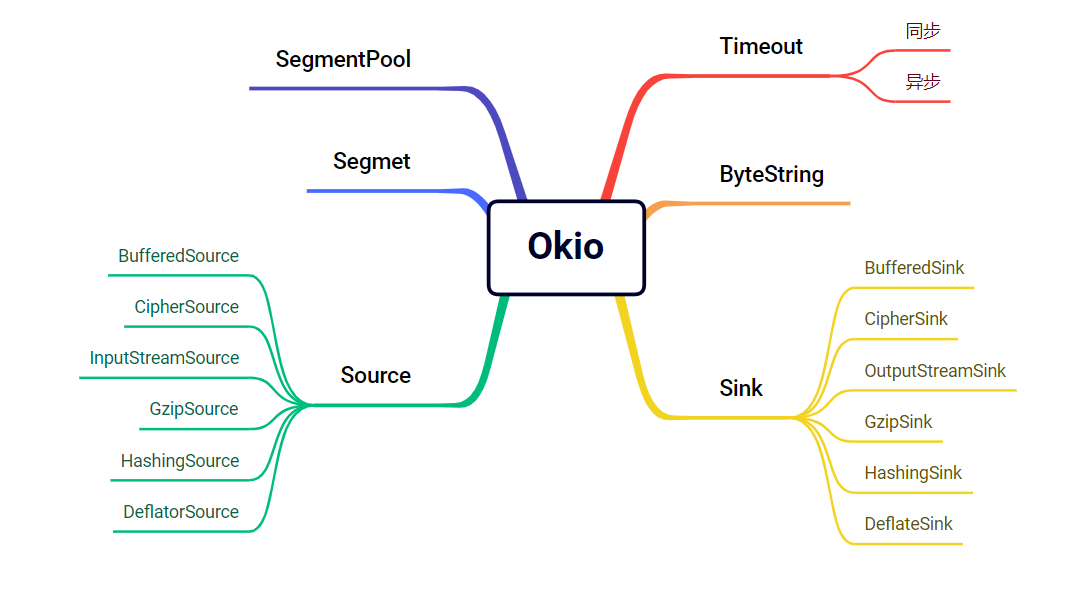
Source
Source类似于OutputStream
Source.read
总的来说比较简单。就是将实现委托给了sink
1
overridefunread(sink: Buffer, byteCount: Long): Long = commonRead(sink, byteCount)
internalinlinefun Buffer.commonReadInt(): Int { if (size < 4L) throw EOFException()
val segment = head!! var pos = segment.pos val limit = segment.limit
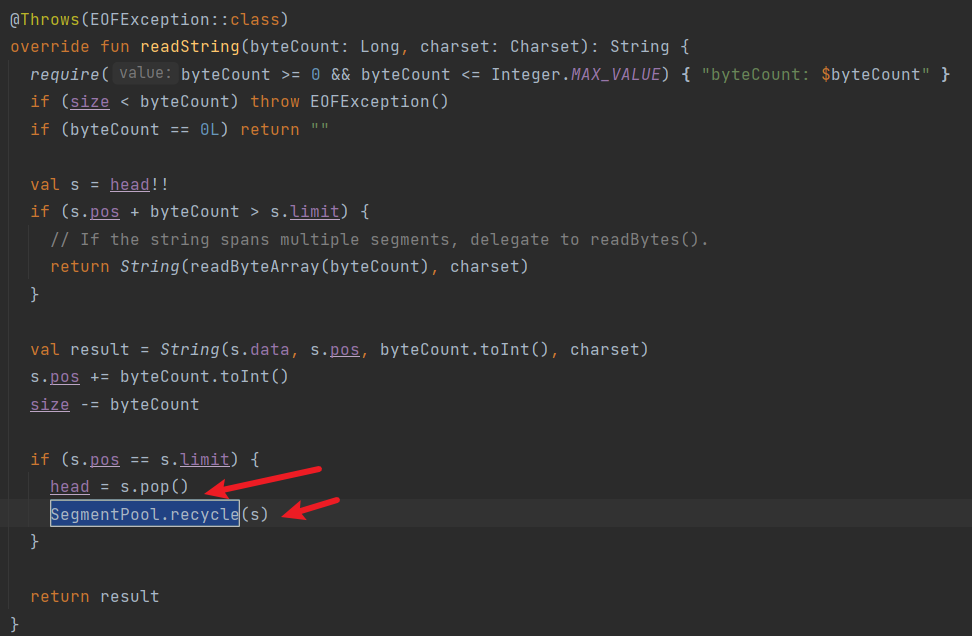
// If the int is split across multiple segments, delegate to readByte(). // segment小于4,按字节读取 if (limit - pos < 4L) { return ( readByte() and 0xff shl 24 or (readByte() and 0xff shl 16) or (readByte() and 0xff shl 8) // ktlint-disable no-multi-spaces or (readByte() and 0xff) ) } // 大于4直接读取segment data valdata = segment.data val i = ( data[pos++] and 0xff shl 24 or (data[pos++] and 0xff shl 16) or (data[pos++] and 0xff shl 8) or (data[pos++] and 0xff) ) // 更新参数 size -= 4L if (pos == limit) { head = segment.pop() SegmentPool.recycle(segment) } else { segment.pos = pos }
return i }
Timeout
无论是Sink还是Source都可以设置超时器。
所谓超时器即超过一定的时间终止任务。
超时器分为两类
同步超时器
当前线程触发中断
异步超时器
异步线程触发中断
同步超时器
即Timeout
设置参数以后在,每一次read/write时都会调用
1 2 3 4 5 6 7 8 9 10
openfunthrowIfReached() { if (Thread.currentThread().isInterrupted) { // If the current thread has been interrupted. throw InterruptedIOException("interrupted") }
funenter() { val timeoutNanos = timeoutNanos() val hasDeadline = hasDeadline() if (timeoutNanos == 0L && !hasDeadline) { return// No timeout and no deadline? Don't bother with the queue. } // 开启计时 scheduleTimeout(this, timeoutNanos, hasDeadline) }
/** Returns true if the timeout occurred. */ funexit(): Boolean { // 任务完成取消计时 return cancelScheduledTimeout(this) }
// 如果计时器第一次开启 if (head == null) { // 初始化watchDog head = AsyncTimeout() Watchdog().start() }
// 计算超时时间 val now = System.nanoTime() if (timeoutNanos != 0L && hasDeadline) { // Compute the earliest event; either timeout or deadline. Because nanoTime can wrap // around, minOf() is undefined for absolute values, but meaningful for relative ones. node.timeoutAt = now + minOf(timeoutNanos, node.deadlineNanoTime() - now) } elseif (timeoutNanos != 0L) { node.timeoutAt = now + timeoutNanos } elseif (hasDeadline) { node.timeoutAt = node.deadlineNanoTime() } else { throw AssertionError() }
// 在队列中以时间排序 val remainingNanos = node.remainingNanos(now) var prev = head!! while (true) { if (prev.next == null || remainingNanos < prev.next!!.remainingNanos(now)) { node.next = prev.next prev.next = node if (prev === head) { // Wake up the watchdog when inserting at the front. condition.signal() } break } prev = prev.next!! } } }